使用Python做验证码识别
平常我们上网经常遇到的验证码英文名为CAPTCHA, 这其实是一个非常炫酷的名字的缩写,全称为全自动区分计算机和人类的图灵测试(英语:Completely Automated Public Turing test to tell Computers and Humans Apart) 。看起来是不是很高大上啊,图灵测试都出来了。不过确实,对于识别验证码这种对人来说很容易的任务(普通验证码,非12306的)对于计算机来说可不简单。
工具
有用的工具:
- PIL(Python Image Library)——图片处理库
- numpy——矩阵运算
- tesseract——开源的ORC库
- scikit-learn——机器学习方面的集成包
分析验证码
验证码也是有计算机生成的,所以不同的验证码有不同的处理方法。所以验证码识别的第一步是观察目标验证码的规律。这次面对的验证码张这样子

一般来说第一步首先是要将验证码图片转换为二值图去除干扰信息,便于进一步处理。 观察分析验证码的字体都是同样的颜色,背景有横的或斜的条纹。直接二值化效果并不好。但是字符之间是没有粘连的,所以我们可以利用这一点提取出字符。
预处理
寻找字符像素
首先第一步是提取出字符的颜色也就是RGB值,观察到字符的颜色相同,占整个验证码图片的比例基本上是差不多的。所以我们可以通过分析像素的直方图找出字符的像素值出来。不过我偷懒没用这样的方法,因为图片开头都是横向的条纹,所以我就直接从左往右扫描图片横向中线的像素值,找出像素值突变的地方就可以找到字符的像素值了。
FloodFill算法提取字符
Flood fill算法是从一个区域中提取若干个连通的点与其他相邻区域区分开(或分别染成不同颜色)的经典算法。处理这种没有粘连字符或者粘连但是字符每个颜色不一样的验证码效果拔群。多说无益,看图就明白了


FloodFill最简单的实现是用递归
def flood_fill(img, x0, y0, blank_color, color_to_fill, cmp_func):
pix = img.load()
pix[x0, y0] = color_to_fill
offsets = [(1, 0), (0, 1), (-1, 0), (0, -1)]
for xoffset, yoffset in offsets:
x, y = x0 + xoffset, y0 + yoffset
try:
if cmp_func(pix[x, y], blank_color):
flood_fill(img, x, y, blank_color)
except IndexError:
pass
不过python不支持尾递归优化,所以运行时回出现异常提示到达最大递归限制。所以改用基于队列的广度优先搜索 实现
def flood_fill2(img, x0, y0, blank_color, color_to_fill, cmp_func):
pix = img.load()
visited = set()
q = queue.Queue()
q.put((x0, y0))
visited.add((x0, y0))
offsets = [(1, 0), (0, 1), (-1, 0), (0, -1)]
while not q.empty():
x, y = q.get()
pix[x, y] = color_to_fill
for xoffset, yoffset in offsets:
x1, y1 = x + xoffset, y + yoffset
if (x1, y1) in (visited):
continue # 已经访问过了
visited.add((x1, y1))
try:
if cmp_func(pix[x1, y1], blank_color):
q.put((x1, y1))
except IndexError:
pass
return visited
字符分割
字符串的分割也是非常重要的一步,对于复杂的验证码,目前还没有非常有效的字符串分割方法。 对于不粘连并且字符之间没有重叠的字符串直接在上下左右四个方向扫描整行或整列是否空白来分割字符
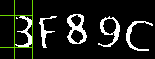
对于字符间有重叠的,如下图的2和F。

一种方法是使用斜向的切割法,但更好的方法还是统计x坐标上的黑白像素占比,在字符分隔处会有白像素占比的波谷。根据这个波谷的来分割图片。
标准化(normalize)
这一步将切割出来的字符摆正并且统一成一样的大小
摆正字符的方法是使用旋转卡壳算法。即从 -30度 ~ 30度旋转图片,检测字符间距,取最小间距对应的角度。

最后在四周填充像素,把所以字符图片统一成一样的尺寸。
识别
Tesseract
识别方面可以使用ORC库tesseract
在安装tesseract后 python使用pytessract方便的调用tesseractF
import pytesseract
from PIL import Image
img = Image.open("captcha.png")
result = pytesseract.image_to_string(img, config='-psm 7')
不过经测试tesseract的对于标准的印刷体的英文识别效果还是可以的,但若有旋转扭曲等扰动等话识别率就不是很高了。不过tesseract通过训练自己的识别模型来提高识别率。
机器学习
另外一个看起来更高大上的方法是应用机器学习的方法来做识别,常用的有SVM和神经网络。
python下机器学习的库首推scikit-learn。scikit-learn里面集成了各种常用的识别模型,降纬,聚类等算法,还要非常棒的文档,可以说是机器学习方面的百宝箱。
使用scikit-learn训练验证码识别模型这事。。。还是先挖个坑,下回再填吧
Reference
http://drops.wooyun.org/tips/141
http://drops.wooyun.org/tips/6313
http://pillow.readthedocs.org/en/3.0.x/reference/Image.html